环境:Ubuntu+TensorFlow
首先是GPU被其他人占用了,怎么也跑不起来最简单的TensorFlow小例子.
所以先学会如何查看显卡使用情况,转去使用其他空闲显卡.
Linux查看Nvidia显卡信息及使用情况
nvidia-smi
结合top,查找进程号对应的用户
Fan:显示风扇转速,数值在0到100%之间,是计算机的期望转速,如果计算机不是通过风扇冷却或者风扇坏了,显示出来就是N/A;
Temp:显卡内部的温度,单位是摄氏度;
Perf:表征性能状态,从P0到P12,P0表示最大性能,P12表示状态最小性能;
Pwr:能耗表示;
Bus-Id:涉及GPU总线的相关信息;
Disp.A:是Display Active的意思,表示GPU的显示是否初始化;
Memory Usage:显存的使用率;
Volatile GPU-Util:浮动的GPU利用率;
Compute M:计算模式;
周期性的输出显卡的使用情况(10s一次)
watch -n 10 nvidia-smi
直接查看哪个用户使用GPU最多 gpustat
pip install git+https://github.com/wookayin/gpustat.git@master --user
gpustat -cu
没有root权限,才加--user,个人觉得超好用!
shell分屏,终端复用软件 Tmux
sudo apt-get install tmux
https://www.cnblogs.com/kevingrace/p/6496899.html
指定空闲的GPU显卡(例如第2块卡)跑程序
在代码前加上:
import os
os.environ['CUDA_VISIBLE_DEVICES']='2'
或者命令行执行程序时:
CUDA_VISIBLE_DEVICES=2 python xxx.py
终于能用GPU了,然后跑了下MNIST with FGSM的例子:mnist_tutorial_tf.py
结果发现 报错了!!
(Loaded runtime CuDNN library: 7.0.4 but source was compiled with: 7.2.1. CuDNN library major and minor version needs to match or have higher minor version in case of CuDNN 7.0 or later version. If using a binary install, upgrade your CuDNN library. If building from sources, make sure the library loaded at runtime is compatible with the version specified during compile configuration.)
查看cuda版本
cat /usr/local/cuda/version.txt
查看cudnn版本
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2
如果显示没有该文件或该路径,就到对应文件中去找
解决方案
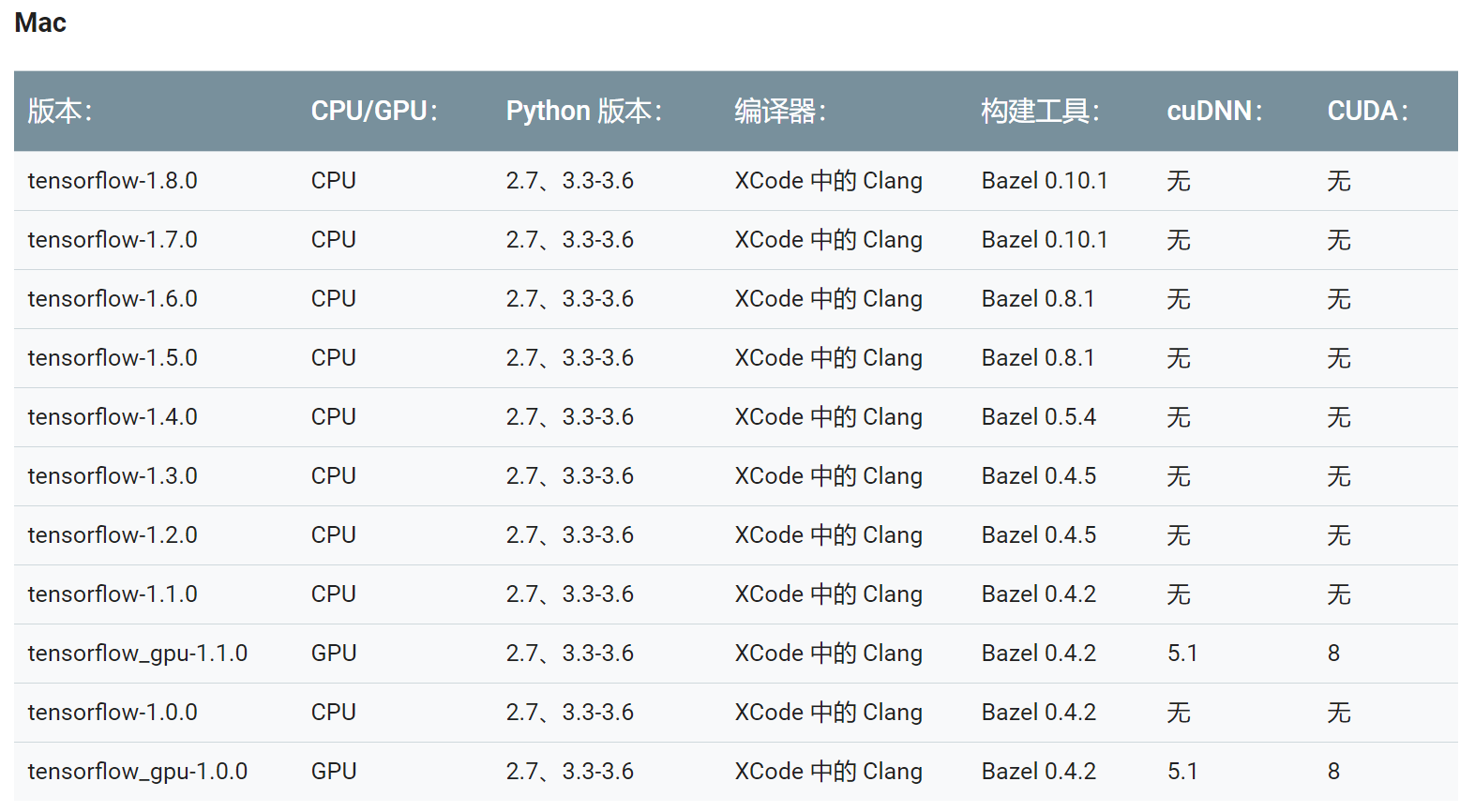
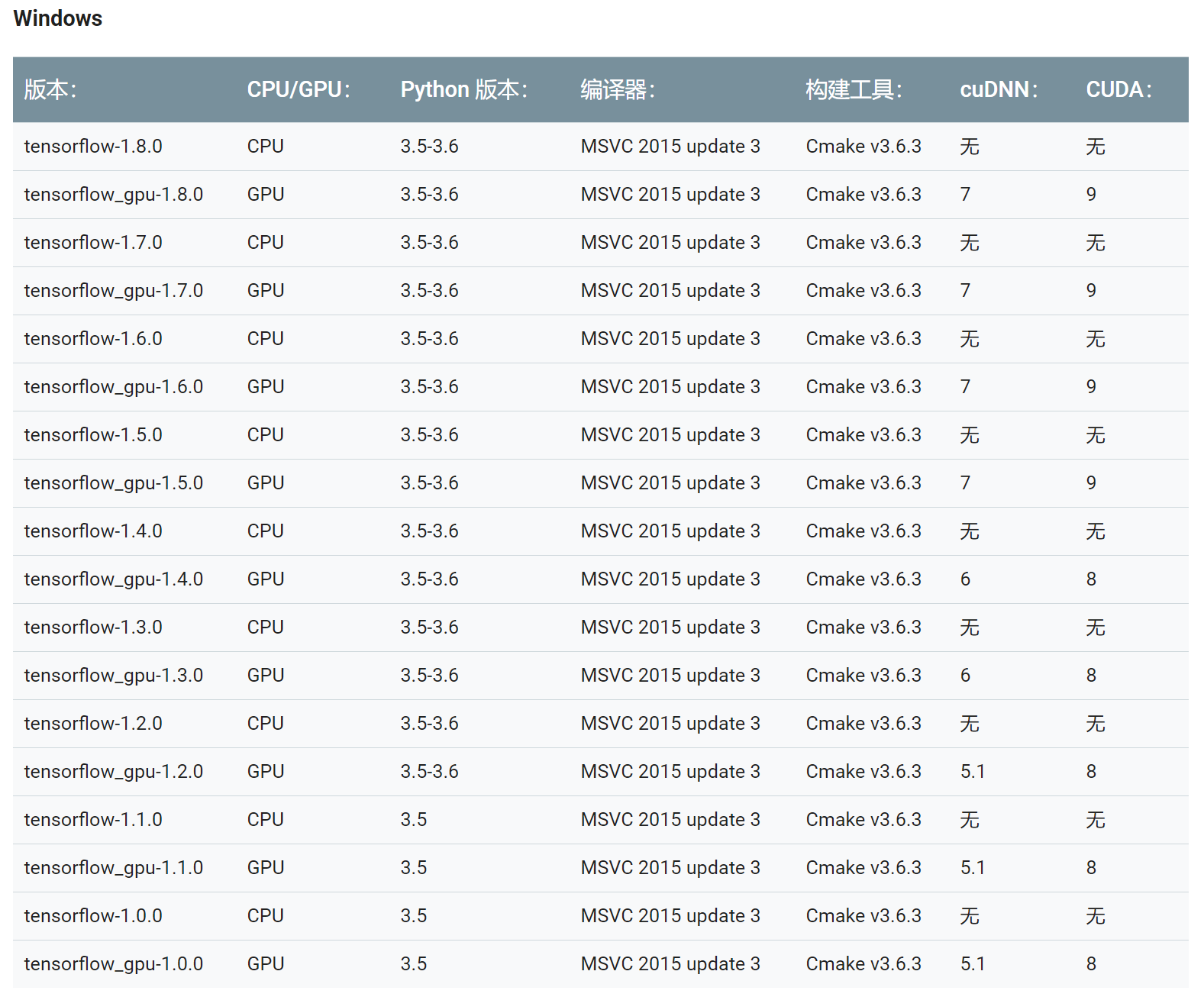
重新安装对应版本的TensorFlow(我安装的TensorFlow1.11.0太高了,cudnn7.04 估计是对应 TensorFlow1.5.0-1.9.0 吧)
pip install --upgrade --force-reinstall tensorflow-gpu==1.9.0 --user
或者安装错误提示中的cudnn对应版本(我没有服务器权限,所以此法较为麻烦)
终于能跑了!!
网上几乎也没有关于CleverHans跑实验的文章,痛苦....
TensorFlow版本对应图
https://www.tensorflow.org/install/source

如果觉得本文还不错的,能成功解决你问题的朋友,请随手点个赞吧~ 评论也可以。
版权声明:本文为博主自主原创,谢绝转载,请尊重个人成果,非常感谢!